説明
重回帰分析
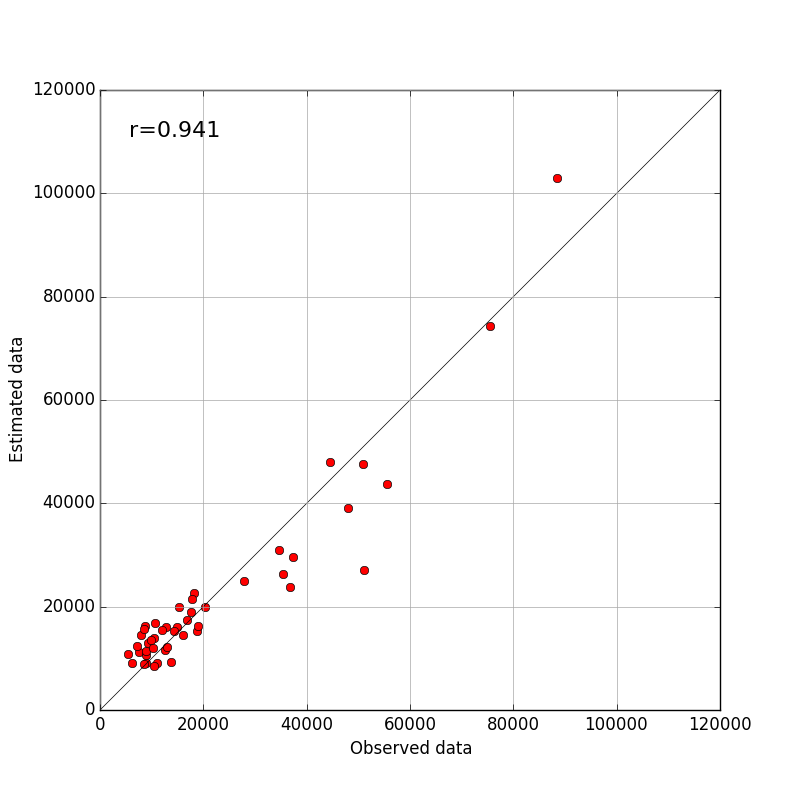
連立方程式の解法の使用事例として,重回帰分析プログラムを作成してみました. 計算のメイン部分は以下の5行です. [xd] は入力データが格納された行列,ベクトル {c} が求める偏回帰係数,{ye} は入力データに偏回帰係数を乗じて求めた回帰推定値,rr が重相関係数です.
a=np.dot(xd.T,xd) b=np.dot(yd,xd) c=np.linalg.solve(a,b) ye=np.dot(xd,c) rr=np.corrcoef(yd,ye)[0][1]
プログラムの使い方は以下のとおり.
python3 py_sta_MRA.py fnameR fnameW
| fnameR | 入力データファイル名 (csv) |
| fnameW | 出力データファイル名 (csv) |
主成分分析
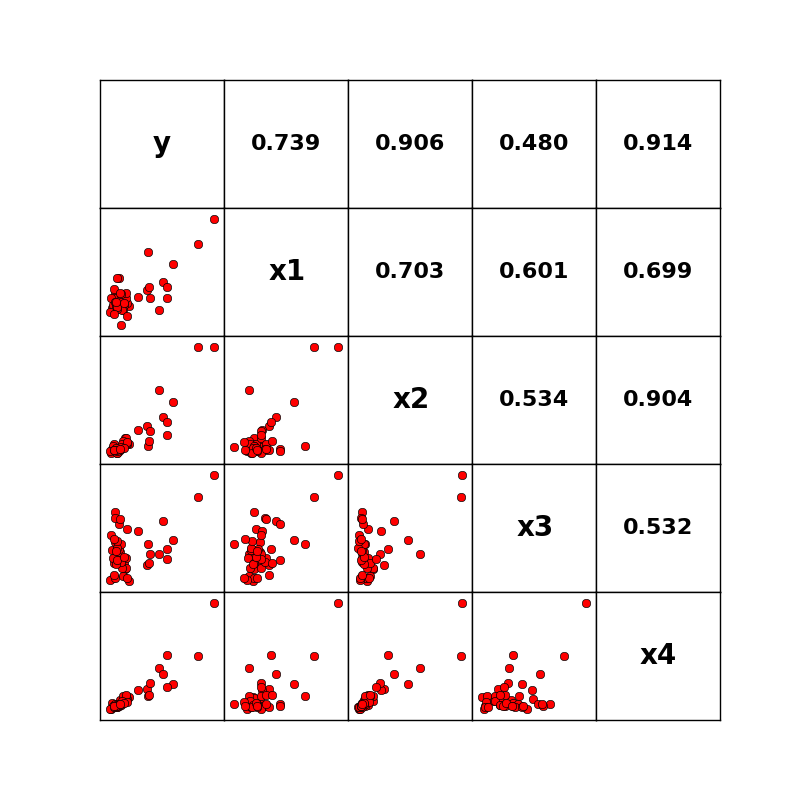
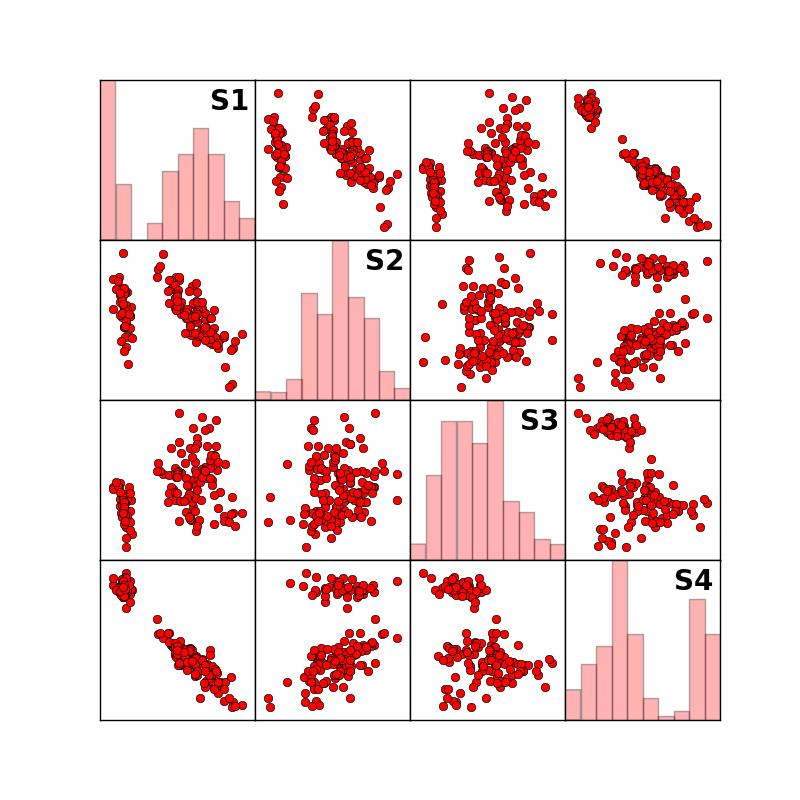
固有値解析の使用事例として,主成分分析プログラムを作成してみました. 計算のメイン部分は以下の3行です. [xd] は入力データが格納された行列,[a] は相関行列,{ev} および [vec] が固有値計算により求まる固有値と固有ベクトルです. [xx] は入力データに固有ベクトルを乗じたものであり,スコアになります.
a=np.corrcoef(xd.T) # correlation matrix ev,vec=np.linalg.eig(a) # Eigenvalue analysis xx=np.dot(xd,vec) # score
プログラムの使い方は以下のとおり.
python3 py_sta_PCA.py fnameR fnameW
| fnameR | 入力データファイル名 (csv) |
| fnameW | 出力データファイル名 (csv) |
クラスター分析 (k−means++法)
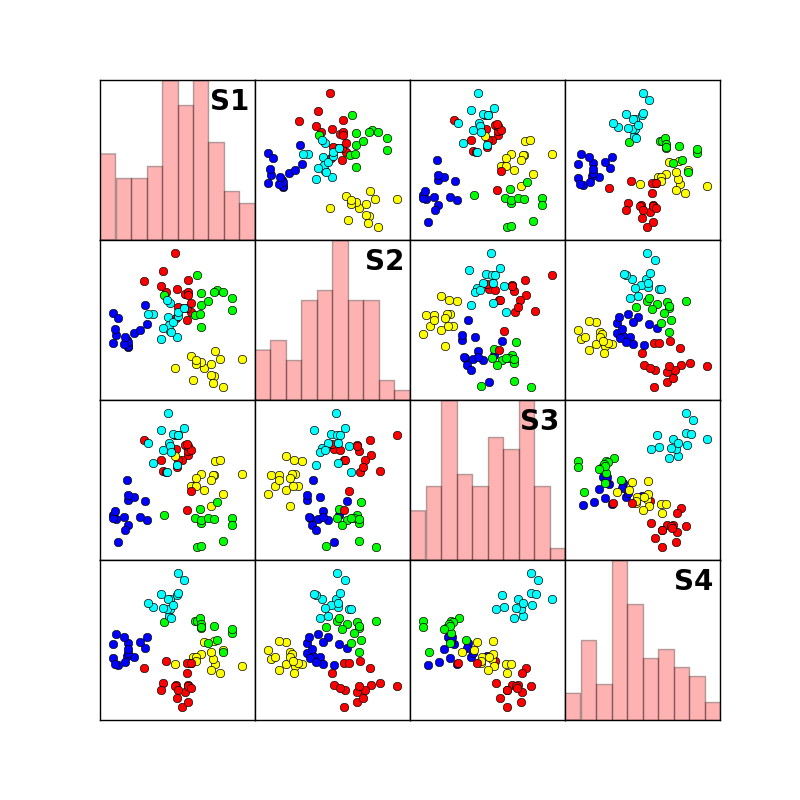
行列・ベクトル演算の練習としてクラスター分析のプログラムを作って見ました. ここでは,クラスタの初期値選定方法を改良した k−means++ 法を用いており,距離計算には Mahalanobis 距離を用いています.計算のメイン部分は主成分分析と同じです. 得られた分類結果は,主成分分析結果で用いたスコア相関図において,分類されたグループ別に色分けして表示しています.
k-means 法の手順
| (1) | 各データにクラスタを割り振る |
| (2) | 割り振ったデータでクラスタの中心を計算する |
| (3) | 各データとクラスタ中心の距離を計算し,最短距離となるクラスタに各データを割り当て直す |
| (4) | 上記を繰り返し,分類が変化しなくなったら計算を終了する |
k-means++ 法における初期値の与え方
| (1) | クラスタ数 k を定め,3個の距離を格納するベクトル {D1},{D2},{DR} を準備する |
| (2) | 1個目の中心点 c1 を,乱数を用いて設定する |
| (3) | ベクトル {D1} に大きな数値をダミーとしてセットする |
| (4) | 中心点 c1 から全点までの距離を計算し,それらをベクトル {D2} に格納する |
| (5) | {D1} と {D2} の要素を比較し,小さい方の値を {DR} に格納する |
| (6) | 2個目の中心点を {DR} の中で最大の距離を有する点として設定する |
| (7) | {D1} = {DR} とおいて,(3) から (6) までのステップを k 個の中心点を得るまで繰り返す |
プログラムの使い方は以下のとおり.
python3 py_sta_KMP.py kk mds itmax fnameR fnameW
| kk | クラスタ数 |
| mds | クラスタ内最小要素数 |
| itmax | 最大繰り返し数 |
| fnameR | 入力データファイル名 (csv) |
| fnameW | 出力データファイル名 (csv) |